tl;dr: My ISP’s CGNAT session timeout is too short, meaning TCP keepalives gets dropped. Test if your own NAT, or your ISP’s CGN, violates RFC5382‘s REQ-5 using this tool: https://github.com/AndersTrier/NAT-TCP-test.
I have been working from home more lately, where I have SSH sessions open to the servers that I’m working on. Often when I return to my computer, or switch to a SSH session that has been sitting idle for a while, the SSH connection is either dead or frozen. If the session is not already dead, the only way to gain control over my terminal again, is to send the ‘terminate connection’ ssh escape sequence <enter>~. after which SSH errors like this:
[email protected]:~$ client_loop: send disconnect: Broken pipe
This happened one day while I was transferring a VM image in the hundreds of gigabytes from one server to another using netcat like so:
ato@host2:~$ nc -l 1337 > hugefile ato@host1:~$ nc -q 1 host2 1337 < hugefile
This transfer would take multiple hours, and when I checked in after it should have finished, my SSH connections had died yet again. And sshd had taken netcat down with it, killing the transfer midway.
That’s when I decided to investigate this problem.
The OpenBSD and OpenSSH developers are known for their extreme focus on code quality. The chances that this problem is caused by a bug in OpenSSH are very slim. (In the same line as “It is (almost) never a compiler error.”)
This is probably a network problem.
I connected my laptop directly to my ISP’s “customer-provided equipment”: a coax modem in bridge mode. Then I ran tcpdump both on my laptop and on the server, and opened a SSH connection. After leaving it idle for about 2 1/2 hours, this is the result:
Client: 100.68.156.34 / 203.0.113.1, server: 130.225.254.99.
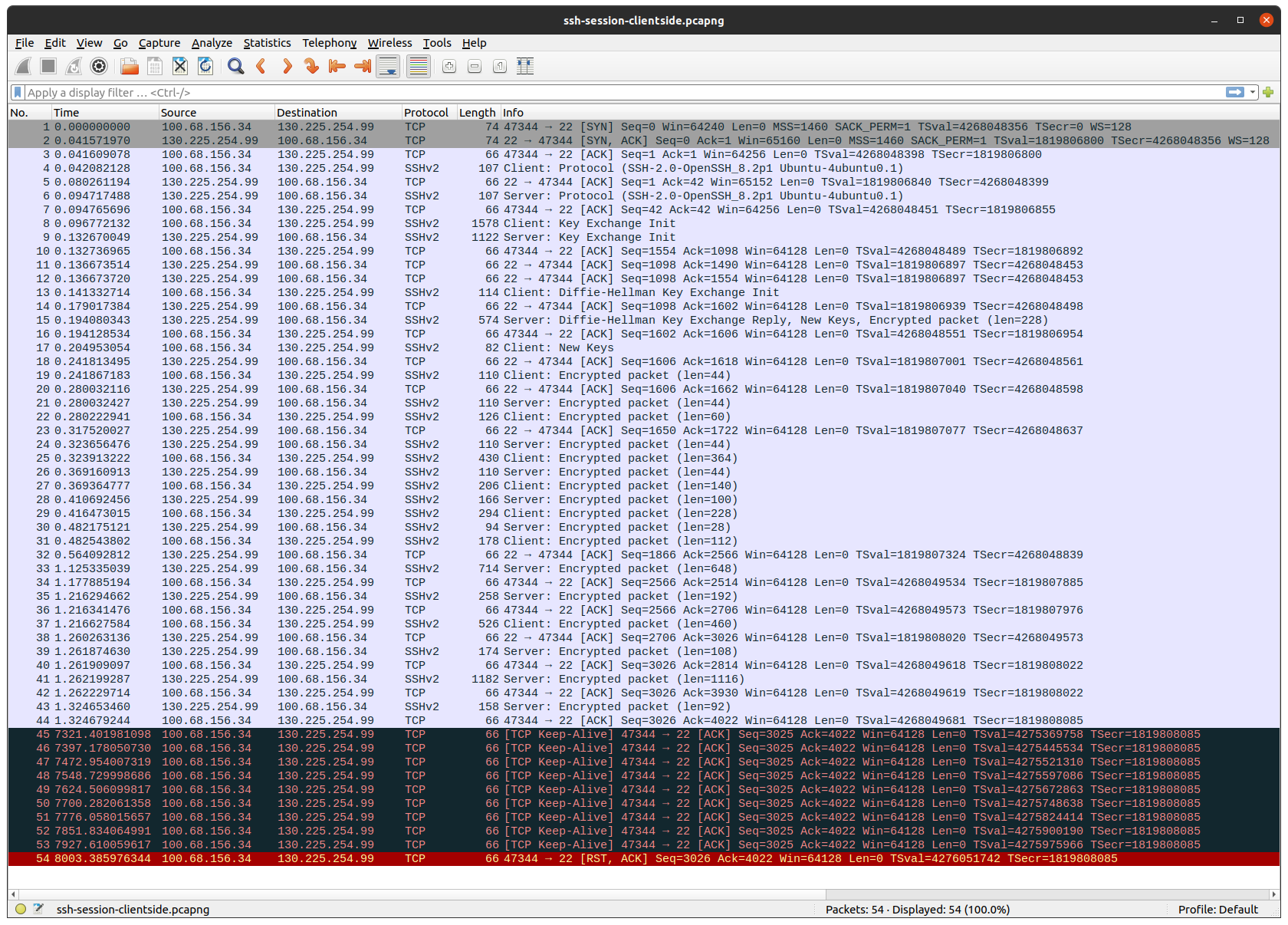
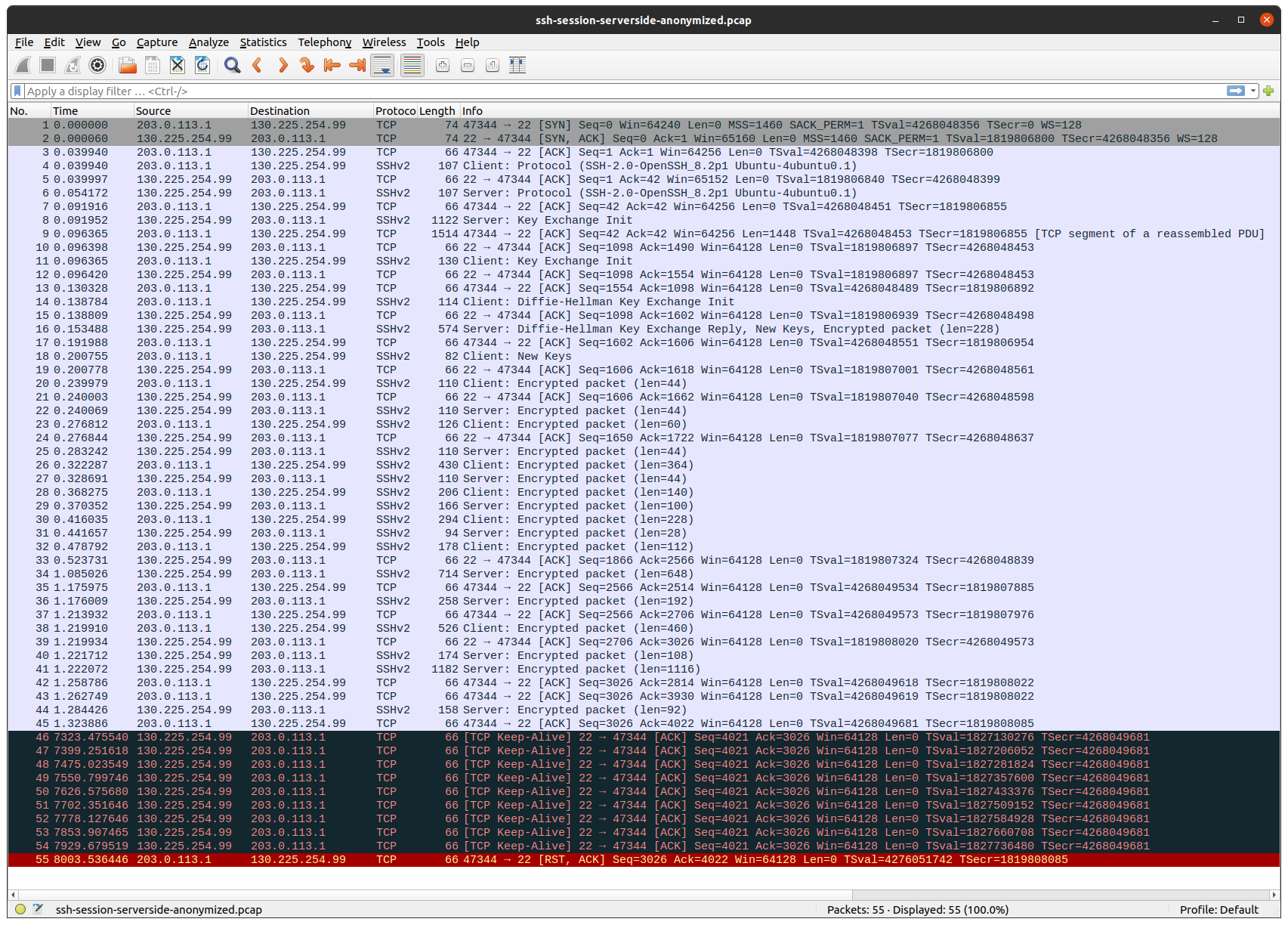
A SSH session does not generate any traffic, unless there’s new output or input. The same is true for TCP. That is why, after the TCP and SSH sessions have been established, no more packages are sent for a long time.
First thing to note, is that my laptop gets an IP in the Carrier-grade NAT address space 100.64.0.0/10, which my ISP then translates to a public internet routable IP. (Because I don’t want to leak my public IP, I used the tcprewrite tool to substitute that IP with one in TEST-NET-3).
Next thing to note, is that after about 2 hours, both the client and the server starts to send TCP-keepalive packages, but none of them come through to the other side.
Finally the client gives up on the TCP session, and sends a TCP reset package, which surprisingly goes through.
Lets see what we can find in the OpenSSH man pages about timeouts and keepalives (ssh_config(5)):
TCPKeepAlive
Specifies whether the system should send TCP keepalive messages to the other side. If they are sent, death of the
connection or crash of one of the machines will be properly noticed. This option only uses TCP keepalives (as op‐
posed to using ssh level keepalives), so takes a long time to notice when the connection dies. As such, you proba‐
bly want the ServerAliveInterval option as well. However, this means that connections will die if the route is down
temporarily, and some people find it annoying.
The default is yes (to send TCP keepalive messages), and the client will notice if the network goes down or the re‐
mote host dies. This is important in scripts, and many users want it too.
To disable TCP keepalive messages, the value should be set to no. See also ServerAliveInterval for protocol-level
keepalives.
ServerAliveInterval
Sets a timeout interval in seconds after which if no data has been received from the server, ssh(1) will send a mes‐
sage through the encrypted channel to request a response from the server. The default is 0, indicating that these
messages will not be sent to the server, or 300 if the BatchMode option is set (Debian-specific).
So TCPKeepAlive enables keepalives handled by the TCP stack implementation (Linux in my case), whereas ServerAliveInterval enables protocol level keep-alives (handled by OpenSSH).
This explains the behavior we’re observing, but also raises new questions:
- Can I fix my problem by enabling the ssh protocol-level-keepalives? (ServerAliveInterval)
- Why are the TCP keepalives only sent after 2 hours?
- Why is my ISP dropping my TCP keepalive packages?
I verified that by setting ServerAliveInterval to 300 (5 min), my problems disappeared. We could stop now that I found a workaround, but let’s keep digging.
The TCP keepalive interval on Linux is configured by net.ipv4.tcp_keepalive_time, which by default is set to 2 hours (7200).
anders@ubuntu-desktop:~$ sysctl net.ipv4.tcp_keepalive_time net.ipv4.tcp_keepalive_time = 7200
Why is it set to two hours? We find our answer in RFC1122:
Keep-alive packets MUST only be sent when no data or acknowledgement packets have been received for the connection within an interval. This interval MUST be configurable and MUST default to no less than two hours.
In the following DISCUSSION section, the RFC writers elaborate on why they (in 1989) think TCP keep-alives only should be sent infrequently:
The TCP specification does not include a keep-alive mechanism because it could:
(1) cause perfectly good connections to break during transient Internet failures;
(2) consume unnecessary bandwidth ("if no one is using the connection, who cares if it is still good?"); and
(3) cost money for an Internet path that charges for packets.
Today the Internet is different from what it was in 1989 when they published that RFC. Now we have NAT everywhere, which is a hack that was accepted on IPv4 because the IPv4 address space is too small. The real solution is IPv6 which has a much bigger address space (2^32 vs 2^128).
NAT (Network Address Translation) allows many computers on a network to share the same IP. This typically works by routing your packet to a device which translates/substitutes your private RFC1918 IP (e.g 192.168.0.0/16) for a public one, and passes on the packet.
CGN (Carrier-grade NAT) is NAT run by an ISP. This allows for many customers to share a single public IP (because even with every household being assigned a single IPv4, we’re still running out). To avoid collisions with the RFC1918 ranges, ISPs are told to use the 100.64.0.0/10 range. With this setup it is not uncommon to have 3 levels of NAT. Ex, CGN, CPE that also does NAT, and the customers own router.
A NAT device must keep track of which connections are made by the clients. This information is stored in the NAT table. Whenever a packet arrives from the Internet, it checks if the packet belongs to a connection in its NAT table, to determine which client to send the package to. If it doesn’t belong to any connections, it drops the packet.
This wouldn’t work if the NAT table only stored IP addresses – which client should the NAT device send the packet to if receiving a packet from a server two of its clients are connected to? That is why – unlike routers – NAT devices have to cross protocol boundaries, and look deeper inside the packet, and find a “transport identifier“. For TCP and UDP the identifiers used are the source and destination port numbers, and for ICMP the Query Identifier is usually used.
A NAT table looks something like this (we’ll ignore ICMP for now):
PROTOCOL SRCIP SRCPORT DSTIP DSTPORT NEWSRCPORT IDLETIME TCP 192.168.1.1 52264 130.225.254.99 22 52264 983 UDP 192.168.1.2 39252 8.8.8.8 53 39252 0
This NAT hack unfortunately opened up Pandora’s box of problems that we are still dealing with today. For example, you can no longer initiate a connection to a computer behind NAT. The NAT device does not know which host to send the packet to. This is why NAT’ing is often equated with firewalling. It is not a feature as such. It is a side effect of the NAT hack.
Back when NAT was introduced, it was not uncommon for protocols to rely on the server establishing a second connection back to the client. In “Active FTP” for example, the server will initiate a new connection back to the client (the data channel) after the client has connected. For this to work the NAT must be even more protocol aware, and preemptively create a mapping for the requested port. The same is true for SIP (used for VoIP) and a few other protocols. This is why most NAT devices can be configured to be FTP and SIP aware. Exactly this feature was recently shown to be a huge security problem – you can trigger this functionality to create a mapping of your choosing from a visitors browser, and connect to any device behind the visitors NAT. Read more about the NAT Slipstreaming attack here.
For big data transfers, or latency sensitive connections (file sharing, VoIP, gaming etc) it is very much preferable to have a direct connection between hosts. But if both hosts are behind a NAT, this is not immediately possible. To solve this problem, a new hack was introduced: NAT hole punching, where you – by using a third-party – can trick your NAT devices to allow traffic directly between the hosts by creating a NAT table entry (“punching” a hole) in both NATs simultaneously. It is only somewhat reliable, and works best with UDP in my experience.
NAT is also one of the reasons the new QUIC protocol uses UDP packages instead of its own protocol. Too many devices will fail to handle the packet correctly if they introduced a new protocol number to use in the IP header. Where should the NAT device look for a transport identifier in an unknown protocol header?
Another problem that arises because of NAT is: when is it safe to remove an entry from the NAT table? Sometimes the answer is simple: when you see that the connection has been closed (e.g the TCP Normal Close Sequence). But when is it safe to remove an established TCP connection (were you haven’t yet seen the connection being closed) on which no packages have been sent for a long time? Lets check what RFC5382: NAT Behavioral Requirements for TCP has to say.
TCP connections can stay in established phase indefinitely without exchanging any packets. Some end-hosts can be configured to send keep-alive packets on such idle connections; by default, such keep- alive packets are sent every 2 hours if enabled [RFC1122]. Consequently, a NAT that waits for slightly over 2 hours can detect idle connections with keep-alive packets being sent at the default rate. REQ-5: If a NAT cannot determine whether the endpoints of a TCP connection are active, it MAY abandon the session if it has been idle for some time. In such cases, the value of the "established connection idle-timeout" MUST NOT be less than 2 hours 4 minutes.
On Linux this timeout is controlled by nf_conntrack_tcp_timeout_established which by default is 5 days. On OpenWRT for example this is lowered to 7440 seconds (2 hours and 4 minutes) to work better on slow hardware.
Alright. Enough rant about NAT. Let’s begin probing my ISP to test if they respect the 2 hours and 4 minutes timeout.
I wrote three different tests which can be found here: https://github.com/AndersTrier/NAT-TCP-test
The idea is to establish a TCP connection to a server, wait some time and then send some data to test if the connection still works. This way we can discover the timeout period before the NAT will drop the connection. Using a single TCP connection at a time, this would take forever. Instead the tests will spawn 130 connections on startup, and test the first connection after 1 minute, the second after 2 minutes and so on (2 hours and 10 minutes total).
tcp-send-test will do exactly that.
tcp-recv-test will instead ask the server to test the connections (i.e be the one to try and send some send data after waiting).
tcp-keepalive-test works essentially the same way as tcp-send-test, but instead of sending actual data, it will use TCP-keepalives. (Maybe my ISP simply drops all keepalive packages?)
By default, the tests are configured to connect to a server sponsored by the non-profit organization dotsrc.org.
This is the output from tcp-send-test when I tested my ISP:
anders@ubuntu-desktop:~/git/NAT-TCP-test$ ./tcp-send-test [+] Trying to establish connections: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 [+] All connections established [+] Connection 0 worked [+] Connection 1 worked [+] Connection 2 worked [+] Connection 3 worked [+] Connection 4 worked [+] Connection 5 worked [+] Connection 6 worked [+] Connection 7 worked [+] Connection 8 worked [+] Connection 9 worked [+] Connection 10 worked [+] Connection 11 worked [+] Connection 12 worked [+] Connection 13 worked [+] Connection 14 worked [+] Connection 15 worked [+] Connection 16 worked [+] Connection 17 worked [+] Connection 18 worked [+] Connection 19 worked [+] Connection 20 worked [+] Connection 21 worked [+] Connection 22 worked [+] Connection 23 worked [+] Connection 24 worked [+] Connection 25 worked [+] Connection 26 worked [+] Connection 27 worked [+] Connection 28 worked [+] Connection 29 worked [+] Connection 30 worked [+] Connection 31 worked [+] Connection 32 worked [+] Connection 33 worked [+] Connection 34 worked [+] Connection 35 worked [+] Connection 36 worked [+] Connection 37 worked [+] Connection 38 worked [+] Connection 39 worked [+] Connection 40 worked [+] Connection 41 worked [+] Connection 42 worked [+] Connection 43 worked [+] Connection 44 worked [+] Connection 45 worked [+] Connection 46 worked [+] Connection 47 worked [+] Connection 48 worked [+] Connection 49 worked [+] Connection 50 worked [+] Connection 51 worked [+] Connection 52 worked [+] Connection 53 worked [+] Connection 54 worked [+] Connection 55 worked [+] Connection 56 worked [+] Connection 57 worked [+] Connection 58 worked [-] Connection 59 is dead (read)
We found the culprit! The connection tested after waiting slightly more than 60 minutes didn’t work, meaning they dropped the connection from their NAT table. 1 hour is too short time for them to wait – they should wait at least 2 hours and 4 minutes. I documented my findings, and sent an email to my ISP. I quickly got a response back acknowledging that this is a bug on their side, and thanking me for my research. They still haven’t fixed the problem though.
The tcp-keepalive-test gave the same result, but strangely enough the tcp-recv-test reported all connections as working. I assume this is because I pay my ISP to have a static public IPv4 mapped to my CGN address. But then why did the server’s keepalive packages get dropped in the SSH example? I speculate that my ISP drops those because they don’t refer to a valid TCP session anymore.
Actually they shouldn’t track my connections at all – they should just forward all packages, and only translate the source or destination IP. But that’s a problem for another day.
If you run the tests, you should start both tcp-send-test and tcp-recv-test. I’ve seen some CGN implementations that only fail the tcp-recv-test.
Here’s what a test looks like with a NAT/CGN that is RFC compliant:
anders@ubuntu-laptop:~/git/NAT-TCP-test$ ./tcp-recv-test [+] All connections established [+] Waiting for the server to close a connection [+] Open connections: 130 [+] Connection 0 returned after 1m 0s: 60 [+] Waiting for the server to close a connection [+] Open connections: 129 [+] Connection 1 returned after 2m 0s: 120 [...] [+] Waiting for the server to close a connection [+] Open connections: 8 [+] Connection 122 returned after 123m 11s: 7380 [+] Waiting for the server to close a connection [+] Open connections: 7 /* no more output produced by the application */
Thanks for reading! I hope you learned something. I’m available for hire. I do computer security and networking. Shoot me an email at hi@<this domain>.
Update: I heard back from my ISP. They told me that the session timeout on their CGN is more than a day, so they continued to investigate the problem (using the tooling I wrote).
They were able to determine that it is actually the cable/coax modem (provided by my ISP) that is killing my idle connections! When put in “bridge mode” it still does connection tracking, and it drops packages which do not belong to any known connections. On this device the idle-timeout is 1 hour. This timeout should be updated to be at least 2 hours and 4 minutes, but it would be even better if it didn’t do any connection tracking at all while in bridge mode.

{kind=link}